테이블 생성스크립트 작성 ( Comment 포함)
선준비사항 (ERWin으로 생성된 Erd 필요, Logical 정보포함)
1. Physical 모드로 변경
2. Database > > Pre & Post Scripts > Model-Level 선택

3. New 선택 후 Script를 넣어줌(comment 같은것)
4. 아래의 내용을 Code에 기입후 OK 클릭
===로지컬을 코맨트로 사용하기===========================
%ForEachTable(){exec sp_addextendedproperty 'MS_Description' , '%EntityName' , 'user' , 'dbo' , 'table' , '%TableName'
go
%ForEachColumn() {
exec sp_addextendedproperty 'MS_Description' , '%AttName' , 'user' , 'dbo' , 'table' , '%TableName' , 'column' , '%ColName'
go}
}
========================================================

===로지컬을 코맨트로 사용하기===========================
%ForEachTable() {
COMMENT ON TABLE %TableName IS '%EntityName';
%ForEachColumn() {
COMMENT ON COLUMN %TableName.%ColName IS '%AttName';
}
}
========================================================

Forward Engineering 시에
5. Tools > Forward Engineer/Schema Generation 선택
6. 우측에 Post-Script 선택 후 OK
7. 다시 Tools > Forward Engineer/Schema Generation 선택후
Preview을 선택하면 Erd의 Logical 정보가 해당코멘트로 달린 Sql 생성스크립트를 볼수 있음.
(mssql 2005에서는 안되는 듯)
* 코멘트가 중복되므로 먼저 해제한다.


** Orthogonal Lines = 직선
** Diagonal Lines = 사선
3) 코딩시작. 단 Sql문과 컬럼명에는 꼭 한글주석을 달도록
대처법 : Oracle 딕셔너리 정보를 이용해 table의 코멘트 정보를 자동생성하는 Generate를 만든다. 1.system 계정으로 처리나 그에 걸맞는 권한을 가진 계정을 가질것
=====================================================
SELECT
A.COLUMN_NAME AS columnName,
A.DATA_TYPE AS dataType,
A.DATA_LENGTH AS dataLength,
B.COMMENTS AS comments,
A.NULLABLE AS nullAble
FROM dba_tab_columns A,
all_col_comments B
WHERE A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
AND A.OWNER = '개발중인 DB 계정'
//AND 조건으로 테이블명 선택시 생성하게끔도 가능
AND A.TABLE_NAME = #tableName#
=====================================================
2. 각 프로젝트의 Framework을 이용해 기본 CURD를 주석과 함께 생성해내는 코드를 작성
----------------------------------------------------------------------------------------------------------------------------------
나와 같은 고민의 흔적들...
아래는 http://www.dbguide.net 의 글을 발췌한 것인데 이제는 링크가 깨진 것 같아 보관용으로 포스팅.
조윤배(iflight) 2004-04-19 22:26:25.0
엔 티티 30개 미만의 소규모 시스템을 개발하고 있습니다. 수많은 글들을 통해 데이터 모델링이 얼마나 중요한지 강조되고 있습니다. 데이터 모델링이 반영된 가장 기본적인 ERD. 프로젝트가 진행되는 도중에 발생하는 ERD와 실제 DB와의 괴리. 이것을 어떻게 좁힐 수 있는지 궁금합니다. ERWin을 통해 데이터 모델링이 이루어진 후, Forward Engineering을 통해서 데이터베이스에 각종 디비 객체를 생성합니다. 그 후 개발이 이루어지며, 밝혀내지 못했던 요구사항이 밝혀지며... 사소한 데이터타입의 변경은 물론 다양한 변화가 발생됩니다.
ERWin 의 Complete Compare 기능은 도저히 못쓰겠습니다. (잘못 쓰고 있는걸까요?) 이때.. 아무리 번거로워도 ERD 와 실제 개발서버의 DB와의 괴리를 어떻게 좁힐 수 있을까요? ERD 의 수작업 밖에는 해결책이 없는것일까요? 새로 리버스 엔지니어링 하기에는, 우리말로 새로 수정해 놓은 논리모델이 리버스엔지니어링 되지 않으므로 한번 ERD가 생성된 이후엔 DB로도, ERD로도 자동으로 업데이트를 기대할 수 없게 되어버렸습니다. 그리고 300여개, 3000여개의 엔티티가 사용되는 대규모 '공사'에는 이러한 문제가 어떻게 다뤄지고 있는지도 궁금합니다.
남효석(whitememil) 07/03/22
Complete Compare의 기능은 충분히 유용합니다.
ERD 즉 데이터 모형과 실제 DB를 항상 동일하게 유지하는 것은 기업의 정보자산 관리를 위해 아주 중요한 문제입니다.ERwin 의 Foward, Reverse Engineering 기능과 함께 Complete compare 기능을 이용하면 모델의 현행화를 쉽게 달성할 수 있습니다.
데이터 모형(ERD)와 DB Schema 간의 현행화는 CASE 툴을 통해서만 가능하다고 할 수 있습니다.
실례로 예전에 대림엔지니어링 모델링 프로젝트에서 담당 DBA에게 이 기능을 잘 교육시켜 모델을 통해 DB변경을 하도록 하였는데 이 DBA는 이를 잘 수행하여 수년뒤 다시 동 회사의 프로젝트를 수행할때 현행화되어 관리되는 모델을 입수할 수 있었습니다. 이는 후속 프로젝트 수행에 많은 도움이 되었습니다.
저 또한 수많은 프로젝트를 수행하면서 프로젝트 수행기간동안의 DB 모형의 변화에 따른 DB 변경을 ERwin을 통해 성공적으로 수행할 수 있었습니다. (ALTER와 ALTER로 변경이 불가능할 경우 기존 테이블의 RENAME한 후 새로 테이블을 생성하고 데이터를 이행해오는 형태로 DB 변경 작업내역을 CASE Tool이 제공해 주어 프로젝트의 변경작업 부하를 상당히 감소시켜 줌)
그러나 CASE Tool을 사용하여 DB 구조 변경 작업이 손쉬운 만큼 실수로 인한 위험도 높다고 할 수 있습니다. 따라서 강력한 Tool을 사용하는 사람은 그 Tool의 사용법을 잘 익히고 사용해야 안전하게 목표한 바를 이룰 수 있다고 할 수 있지요
제가 이를 위하여 주로 사용하는 방법은 Complete Compare를 수행한 후
Import와 Export한 변경항목을 신중히 결정하여 모델의 Import를 수행한 후
DB로 Export하여 반영할 항목은 일단은 ERwin에서 제공하는 변경작업용 sql을 복사하여 editor로 복사한 후 다시 한번 면밀히 검토하여 데이터를 날려먹는 불상사가 발생할 부분이 있는지를 잘 확인한 후 해당 sql을 실행하며 실행 시에도 error발생 시 정지하는 옵션을 유지하여 데이터 이행이 실패하고 RENAME된 테이블까지 날려버리는 불상사를 방지합니다.
이런 오류가 발생하는 주된 경우는 새로 추가한 컬럼이 NOT NULL이거나 하여
기존 데이터 이행 시 오류로 인해 이행이 되지 않는 경우가 대표적이라 할 수 있겠죠.이 경우 CASE Tool이 만들어준 Insert문장에서 해당 컬럼 부분을 유효한 상수값으로(default)값이 들어갈 수 있도록 Insert 문장을 수정하여 실행하면 됩니다.
그리고 reverse로는 논리 모델은 둘째하고라도 한글로 된 속성명과 실체명을 가진 논리 모델은 만들어 낼 수 없으므로 반드시 모델 수정 후 DB로 반영되는 프로세스를 유지하시는 것이 좋습니다.
또 한 현행화 작업이 초반에는 피곤한 작업이나 DB가 안정된 이후에는 변경 항목이 줄어들어 더욱 쉽게 현행화를 할 수 있습니다. 이는 제가 수백개의 테이블을 모델링해야 하는 통신사와 금융업계의 프로젝트를 수행하며 모델링 초기시점부터 프로젝트 종료시점의 안정화 단계까지 진행하며 수년에 걸쳐 확인한 사항이니 ERwin의 기능을 충분히 숙지하고 DB 변경 SQL을 좀더 신중히 검토하며 작업을 수행하면 충분히 가능한 일입니다. 그리고 제대로된 CASE Tool이라면 분명히 지원되어야 할 기능이고 이런 CASE Tool의 기능의 지원이 있어야 대규모 프로젝트에서 모델링 초반에서 안정화 단계에 이르는 변화관리를 제대로 수행할 수 있는 것입니다.
김현(nixor) 04/07/07
저는 항상 이렇게 작업합니다.
1. 논리적모델링 확정(산출물 : 논리 ERD)
2. 물리적DB설계(산출물 : 물리적 ERD)
3. 전체DB스키마 제너레이트하여 스크립트 파일로 보관(트리거,스토어드 등 모두 포함)
4. 테스트 데이타입력모듈 작성/보관
5. ERWin의 포워드 엔지니어링후, 테스트 데이터입력.
-------------------------------> 여기까지가 개발준비과정으로 보통 1주일정도 소요된다..
데이터이행등까지 합하면, 아주 늦으면, 2주정도..
6. 물리ERD보면서, 개발진행(ERD프린트는 하지 않는다..문서관리 하기 힘드니까..ERWin그대로 열어놓고 작업한다..)
7. DB스키마 변경발생시, 변경부분을 작업중인 팀원들에게 일단 "변경후에" 작업하라고 지시한후, 산출물인 논리ERD수정/물리ERD수정 후, 팀원들에게 "지금 DB 다 날리고 새로 생성합니다" 라고 한후, 길어야 3분만에 새로생성.. 새로이 ERWin의 포워드엔지니어링 실시후, 테스트 대이터 입력
8. 필요시 7번항목 반복
9. 개발완료시, 테스트용 데이터 모두 삭제, 오픈준비 즉, 개발중에 관리할 산출물은 논리/물리 ERD, 테스트데이터입력모듈, 테스트데이터 4가지 입니다..
몇 번 해보면, 일의 순서가 몸에 익을것입니다...즉 항상 개발중인 DB는 날릴 각오를 하고, 언제든지 변경이 반영된 스크립트로 순식간에 새로 생성할 준비를 해두면서 개발하면 정말 깔끔한 개발이 됩니다.. 요즘은 논리적 ERD는 엔코아의 DA# 모델러로 작업합니다...정말 논리적으로 정리가 잘되거든요(특히 서브타입같은경우..). DA# 디자이너는 SQL Server가 지원되지 않는것 같아서, 아직 사용하지 못하고 있습니다..
안희정(anheejung) 04/04/20
안녕하세요? 엔코아정보컨설팅의 안희정입니다.
ERD와 실제 DB의 동기화에대한 자동화에는 근본적인 한계점이 있다고봅니다.
테 이블은 개체로 변환하더라도 테이블들간에 Referential integrity Rule을 적용해놓지 않으면 데이터베이스 딕셔너리로부터 그 테이블들간에 릴레이션쉽까지 자동화해서 표현할 수 는 없을 것 입니다. 하지만 꼭 필요한 일부 경우에만 RI rule을 적용하여 운영하는 경우가 많은것이 현실 입니다.
또한 ERWin 의 경우는 물리적인 테이블하나가 곧 엔터티 하나와 대응되는 논리모델과 물리모델이 같은 구조로 되어있으면서 논리모델은 속성명으로 물리모델은 컬럼명과 데이터타입을 볼수 있는 형태로 되어있지만 엄밀히 말해 논리모델 = 물리모델은 아니므로 논리모델에서 하나로 통합된 엔터티가 물리적인 측면을 고려하여 n개의 테이블로 생성될수 도 있으므로 논리모델과 물리모델을 각기 표현해주는 저희 회사의 DA# Modler와 Designer에서는 데이터베이스의 구조만으로 자동으로 완벽한 논리모델을 표현하는데는 한계점이 있다는 것입니다.
물론 DB 스키마와 물리ERD를 compare해서 차이점을 notify하는 기능은 지원해야하지만 오로지 툴에의존해서 논리모델을 얻어낸다는것은 무리가 있다고 봅니다.
또 한 서브타입의 표현등 인간의 판단이 들어가는것까지를 수작업이라고 보신것인지는 모르겠습니다만, 제가 컨설팅한 사이트의 예를 들어보면 DB에 오브젝트를 생성할 수 있는 권한을 가진 user와 개발자들이 사용할 user를 분리하여 개발자들에게는 그 오브젝트에대한 DML만 사용할 수 있는 권한을 부여하고 데이터모델은 한명의 책임자를 통해 관리하므로써 요구사항변경등에 따른 모델의 변경이 있을때는 논리모델 ERD에 먼저 반영을 한후 Designer를 통해 변경된 컬럼명과 데이터타입정보만 maintenance 하므로써 오브젝트생성권한의 user로 Forward Engineering을 통해 오브젝트를 생성하도록 하여 실제DB와 ERD를 동기화하도록 하였습니다.
변경사항이 발생했을때 DB 오브젝트부터 변경하는것이 아니라 우선적으로 ERD에 반영을 한후 오브젝트를 생성하는것이 괴리를 최대한 줄일 수 있는 방법이라고 봅니다.
[개요]
ERWin을 쓰다보면, 관계선(Relation Line)의 위치를 변경해야할 경우가 발생한다.
그럴때 직접 마우스로 드래그해서 위치를 변경하려고 하면 변경되지 않을 경우가 있는데, 그건 옵션에서 수동으로 변경되지 않도록 설정이 되어 있기 때문이다.
수동으로 위치를 직접 변경하고 싶으면 아래와 같은 절차에 따라서 옵션을 변경하면 된다.
1. 메뉴 > Format > Preferences...로 이동
2. Layout 탭 > Relationship Line Layout 에서 Allow menual layout 를 체크

3. OK 클릭
<출처: http://blog.naver.com/PostView.nhn?blogId=hushath&logNo=100019067680 >
대부분 디비 스크마 설계시에 ERWIN을 사용하는데요...
설계만 ERWIN에서 하고 설계 내용을 적용할시에는 직접 오라클에 접속을 해서
하더라구요. 그러니까 예를 들어 설명을 하면 ERWIN에서 새테이블을 생성하고
이것을 다시 오라클에 접속을 해서 테이블을 생성하는 개발자로 많이 보았습니다.
하지만 ERWIN에는 자신의 로컬피씨에 있는 ER1파일과 오라클 디비 서버와 접속을 해서
바로 반영할수 있는 기능이 있습니다.
메뉴에 Tools 아래에 다음과 같은 메뉴가 있습니다.
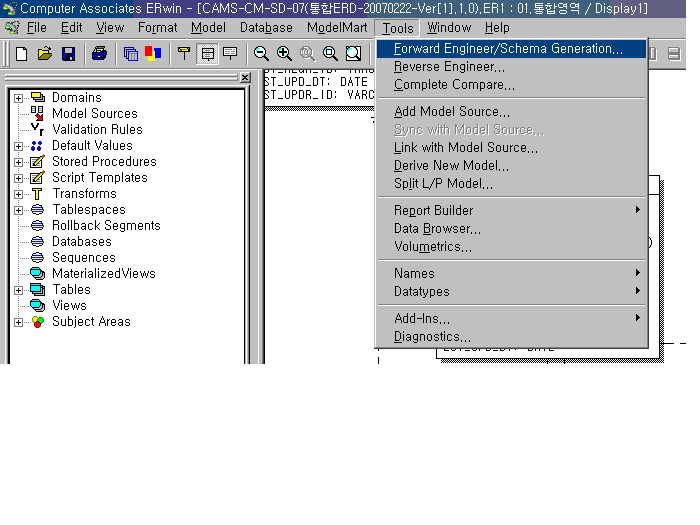
Forward Engineering/Schema Generation
Reverse Engineering
Complete Compare
설명을 하자면~
Forward Engineering/Schema Generation
자신의 피씨에 있는 er1 파일을 오라클 디비서버에 반영합니다. 주로 처음 데이터베이스 생성해서
테이블을 만들때 사용합나디.
Reverse Engineering
오라클 디비서버에 있는 내용을(테이블, 프로시저등등...) 자신의 로컬피씨 er1으로 내려 받아 생성합니다.
Complete Compare
로컬피씨에 있는 er1파일과 오라클 디비서버와 객체를(테이블, 컬럼, 프로시저 등등...) 비교합니다.로컬피씨에 er1파일을 오라클 디비서버로 반영할수 있고 반대로 오라클 디비서버에서 로컬피씨의 er1파일로 반영할수 있습니다.이 글을 읽는분이 대부분 개발자 이므로 자세한 옵션 기능은 생략하겠습니다.몇번 시행 착오를 겪고 하다보면은 바로 할수 있으리가 생각합니다.
참조:
http://www.okjsp.pe.kr/seq/99380
http://chez.egloos.com/1719907
http://www.genesis.co.kr/php/technote6/board.php?board=freeboard
'Tech' 카테고리의 다른 글
| speed up Outlook 2007 (0) | 2008.10.14 |
|---|---|
| 설계도면그리기 - Visio (0) | 2008.10.04 |
| ERWin Report builder (0) | 2008.09.18 |
| FTP (0) | 2008.09.09 |
| ERWin (0) | 2008.09.08 |
| Google Earth (0) | 2008.09.01 |